Kedro — A framework for building production ready Data Science pipelines

Table of Contents
- Introduction
- Key Features of Kedro
- Installation
- Core Concepts
i. Node
ii. Pipeline
iii. Data Catalog
iv. Project Directory Structure - AG News Classification task — Kedro Project
i. Project Setup
ii. Data Setup
iii. Testing Registered Data
iv. Data Processing Pipeline
v. Data Science Pipeline
vi. Kedro Visualization
vii. Packaging kedro project
viii. Deploying kedro package
Introduction
Kedro is an open source Python framework for creating reproducible, maintainable and modular data science code. It uses best practices of software engineering to build production ready data science pipelines. Advantages of using Kedro are:
- Machine Learning Engineering: It borrows concepts from software engineering and applies them to machine-learning code. It is the foundation for clean, data science code.
- Handles Complexity: Provides the scaffolding to build more complex data and machine-learning pipelines.
- Standardisation: Standardises team workflows; the modular structure of Kedro facilitates a higher level of collaboration when teams solve problems together.
- Production-Ready: Makes a seamless transition from development to production, as you can write quick, throw-away exploratory code and transition to maintainable, easy-to-share, code experiments quickly.
Key Features of Kedro
- Pipeline Visualisation: Kedro’s pipeline visualisation plugin shows a blueprint of your developing data and machine-learning workflows, provides data lineage, keeps track of machine-learning experiments and makes it easier to collaborate with business stakeholders.
- Data Catalog: A series of lightweight data connectors used to save and load data across many different file formats and file systems with support for different file formats
- Integrations: It integrates easily with Apache Spark, Pandas, Dask, Matplotlib, Plotly, fsspec, Apache Airflow, Jupyter Notebook and Docker.
- Project Template: It helps in standardizing how configuration, source code, tests, documentation, and notebooks are organised with an adaptable, easy-to-use project template
- Pipeline Abstraction: Kedro supports a dataset-driven workflow that supports automatic resolution of dependencies between pure Python functions.
- Coding Standards: Test-driven development using pytest, produce well-documented code using Sphinx, create linted code with support for flake8, isort and black and make use of the standard Python logging library.
- Flexible Deployment: It allows different deployment strategies like single or distributed-machine deployment as well as additional support for deploying on Argo, Prefect, Kubeflow, AWS Batch, AWS Sagemaker, Databricks, Dask and more.
- Experiment Tracking: Experiment tracking records all the information you need to recreate and analyse a data science experiment.
Installation
Kedro can be installed from PyPi repository using the following command:
pip install kedro # core package
pip install kedro-viz # a plugin for visualizationIt can also be installed using conda with the following command:
conda install -c conda-forge kedroTo confirm whether kedro is installed or not, type the following command in command line and you can verify the installation by seeing an ASCII art graphic with kedro version number:
kedro info
Core Concepts
Node
In Kedro, a node is a wrapper for a pure Python function that names the inputs and outputs of that function. Nodes are the building block of a pipeline, and the output of one node can be the input of another.
Pipeline
A pipeline organises the dependencies and execution order of a collection of nodes and connects inputs and outputs while keeping your code modular. The pipeline determines the node execution order by resolving dependencies and does not necessarily run the nodes in the order in which they are passed in.
Data Catalog
The Kedro Data Catalog is the registry of all data sources that the project can use to manage loading and saving data. It maps the names of node inputs and outputs as keys in a DataCatalog (a Kedro class that can be specialised for different types of data storage).
Project Directory Structure
The default template followed by kedro to store datasets, notebooks, configurations and source code is shown below. This project structure makes it easier to maintain and collaborate on the project easily. It can also be customized based on our needs.
project-dir # Parent directory of the template
├── .gitignore # Hidden file that prevents staging of unnecessary files to `git`
├── conf # Project configuration files
├── data # Local project data (not committed to version control)
├── docs # Project documentation
├── logs # Project output logs (not committed to version control)
├── notebooks # Project-related Jupyter notebooks (can be used for experimental code before moving the code to src)
├── pyproject.toml # Identifies the project root and [contains configuration information]
├── README.md # Project README
├── setup.cfg # Configuration options for `pytest` when doing `kedro test` and for the `isort` utility when doing `kedro lint`
└── src # Project source codeAG News Classification task — Kedro Project
Let’s understand how to setup and use Kedro by going through step by step tutorial of creating a simple text classification task :)
Project Setup
It is always better to create a virtual environment to prevent any conflicts in environment package. Create a new virtual environment and install kedro from the above commands. To create a new kedro project enter the following command in command line and enter a name for the project:
kedro newFill in the name of the project as “kedro-agnews-tf” in the interactive shell. Then, go to the project and install the initial project dependencies using the command:
cd kedro-agnews-tf
pip install tensorflow
pip install scikit-learn
pip install mlxtend
pip freeze > requirements.txt # update requirements fileWe can setup logging, credentials and sensitive information in conf folder of the project. Currently we do not have any in our development project, but this becomes crucial in production environments.
Data Setup
Now, we setup the data for our development workflow. The data folder in the project directory hosts multiple sub-folders to store the project data. This structure is based on layered data-engineering convention as a model of managing data (For in-depth information, checkout this blogpost). We store the AG News Subset data (downloaded from here) into raw sub-folder. The processed data goes into other sub-folders like intermediate, feature; trained model goes into model sub-folder; model outputs and metrics go into model_output and reporting sub-folders respectively.
Then, we need to register the dataset with kedro Data Catalog i.e. we need to reference this dataset in conf/base/catalog.yml file which makes our project reproducible by sharing the data for the complete project pipeline. Add this code to conf/base/catalog.yml file (Note: we can also add to conf/local/catalog.yml file)
# in conf/base/catalog.yml
ag_news_train:
type: pandas.CSVDataSet
filepath: data/01_raw/ag_news_csv/train.csv
load_args:
names: ['ClassIndex', 'Title', 'Description']
ag_news_test:
type: pandas.CSVDataSet
filepath: data/01_raw/ag_news_csv/test.csv
load_args:
names: ['ClassIndex', 'Title', 'Description']Testing Registered Data
To test whether kedro can load the data, type following command in command line:
kedro ipythonType the following in the IPython session:
# train data
ag_news_train_data = catalog.load("ag_news_train")
ag_news_train_data.head()
# test data
ag_news_test_data = catalog.load("ag_news_test")
ag_news_test_data.head()After validating the output, close the IPython session using the command: exit(). This shows that data has been registered with kedro successfully. Now, we move on to the pipeline creation stage where we create Data processing and Data Science pipelines.
Pipeline Creation
Now, we create python functions as nodes to construct the pipeline and run these nodes sequentially.
Data Processing Pipeline
In the terminal from project root directory, run the following command to generate a new pipeline for data processing:
kedro pipeline create data_processingThis generates following files:
src/kedro_agnews_tf/pipelines/data_processing/nodes.py(for the node functions that form the data processing)src/kedro_agnews_tf/pipelines/data_processing/pipeline.py(to build the pipeline)conf/base/parameters/data_processing.yml(to define the parameters used when running the pipeline)src/tests/pipelines/data_processing(for tests)
The steps to be followed are:
- add data preprocessing nodes (python functions) to nodes.py
- assemble the nodes in the pipeline.py
- add configurations in data_processing.yml file
- register the preprocessed data into conf/base/catalog.yml
To keep this blog succinct, I have not added the code that needs to be added to each of the file here. You can checkout the code that needs to be added for each of the files in my GitHub repository here.
Run the following command to validate if you are able execute the data processing pipeline without any errors:
kedro run --pipeline=data_processingThe above code generate data in data/02_intermediate and data/03_primary folders.
Data Science Pipeline
In the terminal from project root directory, run the following command to generate a new pipeline for data science:
kedro pipeline create data_scienceThis commands generates similar files as to when the data processing pipeline command had been run, BUT now files will be generated for data science pipeline.
The steps to be followed are:
- add model training and evaluation nodes (python functions) to nodes.py
- assemble the nodes in the pipeline.py
- add configurations in data_science.yml file
- register the model and results into conf/base/catalog.yml
You can checkout the code that needs to be added for each of the files in my GitHub repository here.
Run the following command to validate if you are able execute the data science pipeline without any errors:
kedro run --pipeline=data_scienceThe above code generates model and results in data/06_models and data/08_reporting folders respectively
This completes the data science pipeline. If you are interested further to build project documentation, use Sphinx to build the documentation of your kedro project.
The data folder contains different dataset starting from raw data, intermediate data, features, models etc. It is highly advised to use DVC (Data Version Control) to track this folder which offers lots of benefits. (You can checkout my blog on getting started with DVC here)
Kedro Visualization
We can visualize our complete kedro project pipeline using Kedro-Viz, a plugin built by Kedro developers. We have already installed this package during initial installation (pip install kedro-viz). To visualize our kedro project, run the following command in the terminal in the project root directory:
kedro vizThis command opens a browser tab to serve the visualization (http://127.0.0.1:4141/). The below image shows the visualization of our kedro-agnews project:
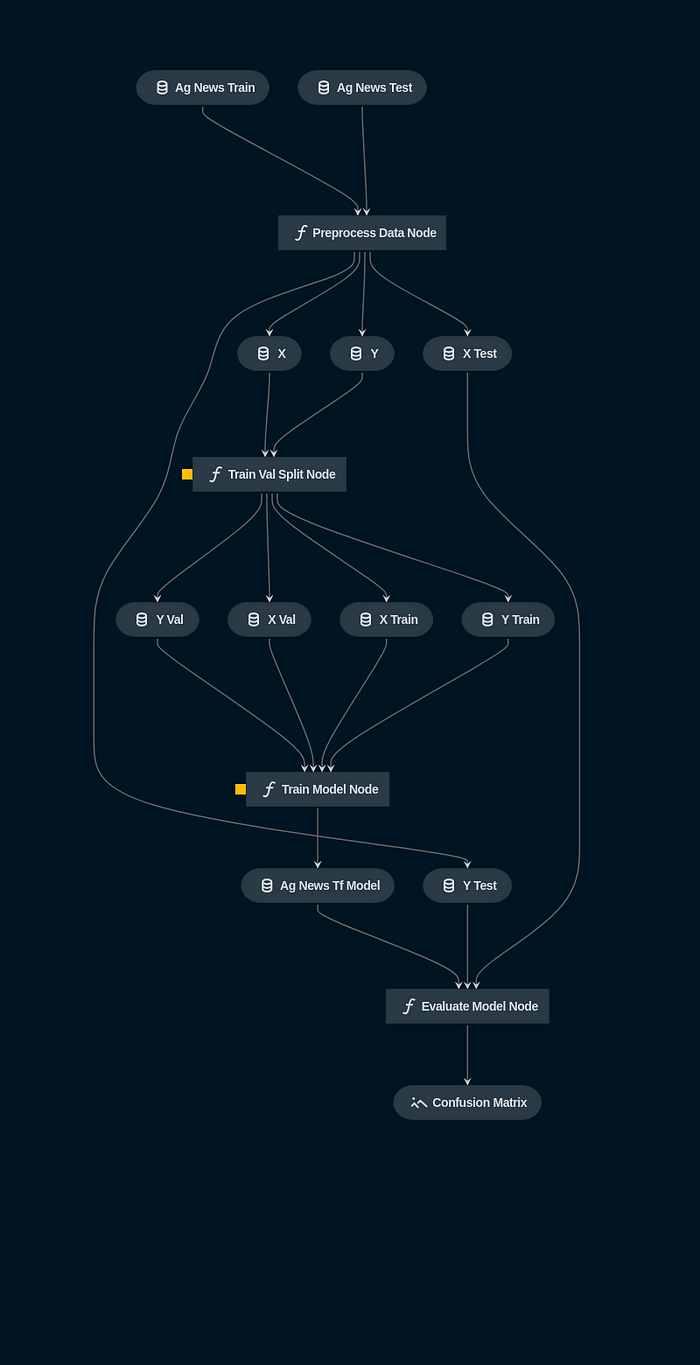
You can click on each of the nodes and datasets in the visualization to get more details of them. This visualization can also be refreshed dynamically as when the the Python or YAML file changes in the project, by using the option--autoreload in the command
Packaging kedro project
To package kedro project, run the following in the project root directory:
kedro packageKedro builds the package into the dist folder of your project, and creates one .egg file and one .whl file, which are Python packaging formats for binary distribution.
Deploying Kedro Package
To deploy the kedro packaged pipelines, we can use kedro plugins to deploy to various deployment target:
- Kedro-Docker: For packaging and shipping kedro projects within docker contains
- Kedro-Airflow: Converting kedro projects into Airflow project
- Third party plugins: Community developed plugins for various deployment targets like AWS Batch and Prefect, AW SageMaker, Azure ML Pipelines etc
To run the project directly, you can checkout my GitHub repository here, and run the following commands:
git clone https://github.com/dheerajnbhat/kedro-agnews-tf.git
cd kedro-agnews-tf
tar -xzvf data/01_raw/ag_news_csv.tar.gz --directory data/01_raw/
pip install -r src/requirements.txt
kedro run
# for visualization
kedro vizI hope this will help you get started with Kedro :)
References:
[1] https://github.com/kedro-org/kedro
[2] https://kedro.readthedocs.io/en/stable/index.html
[3] https://kedro.org/